Q 1: How do I contact support?
A: You can contact support at [email protected]
Q 2: How accurate is the extraction?
A: Accuracy depends on PDF quality and structure. For well-formatted native text PDFs (like digital invoices), accuracy is typically 90-95%. For scanned documents, accuracy depends on scan quality and may be lower. Each extracted field comes with a confidence score so you can flag low-confidence results for manual review.
Q 3: What types of PDFs does it handle?
A: Both native text PDFs (generated by software) and scanned/image PDFs (which require OCR). Native text PDFs will produce better results. Heavily formatted, multi-column, or visually complex PDFs may require post-processing.
Q 4: How does it compare to AWS Textract?
A: Textract is more powerful and handles a wider variety of documents, especially with its custom queries feature. However, Textract requires AWS infrastructure knowledge, has complex pricing (per page, per feature), and can be expensive at scale. ParseFlow is simpler: one API, one price, focused on the most common extraction tasks.
Q 5: Is there a page limit?
A: The LTD includes 2,000 pages/month processing. A single multi-page document counts as multiple pages. If you need higher volume, contact us for custom pricing.
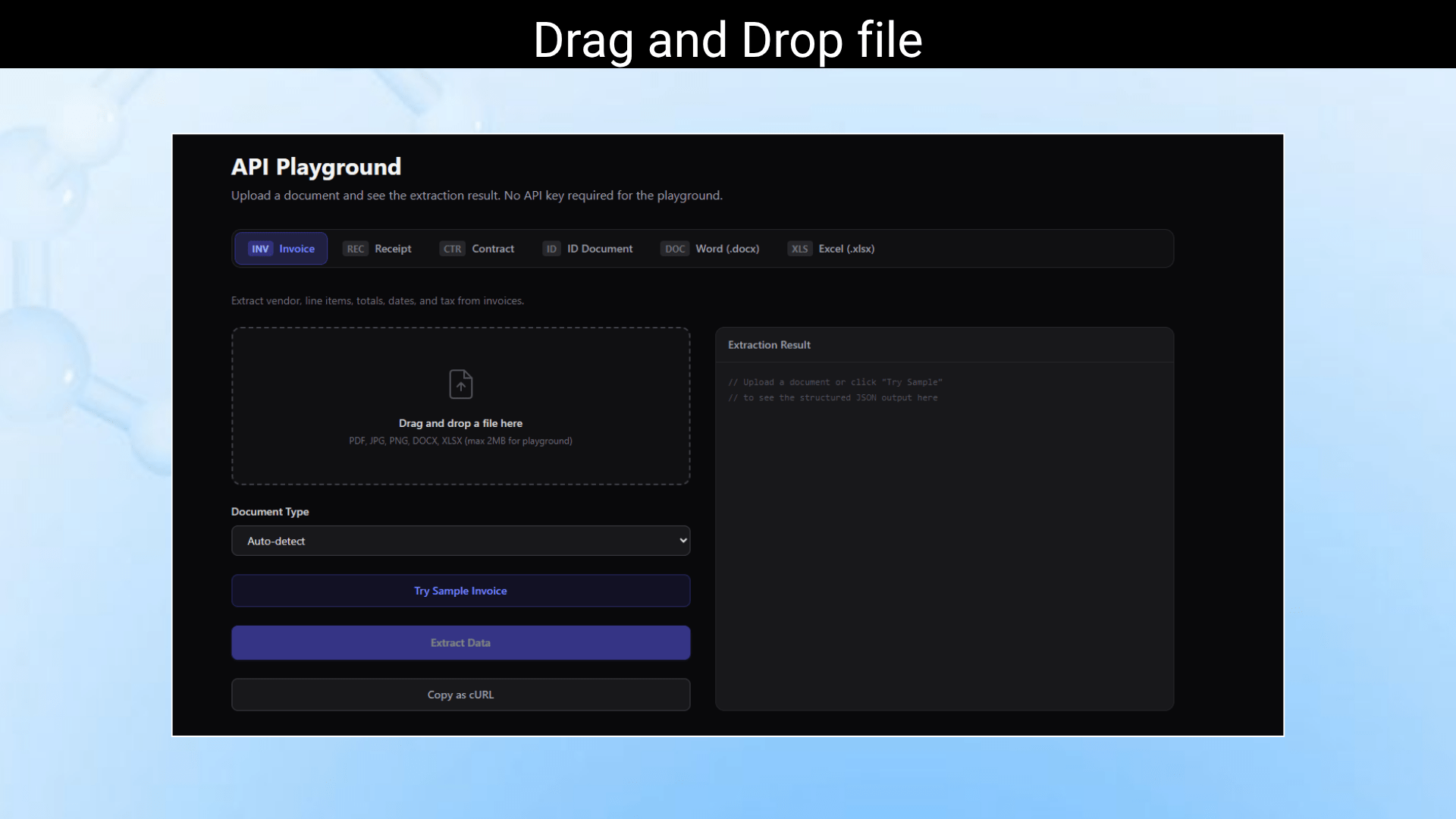
Q 6: Can I extract data from specific fields only?
A: Yes, You can specify which fields you want extracted (e.g., “total_amount”, “invoice_date”, “vendor_name”) to get targeted results rather than full document extraction.
Q 7: Does it support languages other than English?
A: The OCR engine supports major Latin-script languages. Support for non-Latin scripts (Chinese, Japanese, Arabic, etc.) is planned for Q3 2026.



Reviews
There are no reviews yet.